Journal Updates
As part of the Canadian Distributed Mentorship Program, here is where I will be posting my journal entries relating to the work done.
| I - | II - | III - | IV - | V - | VI - | VII - | VIII - | IX- | X- | XI- | XII- | XIII- | XIV- | XV- | XVI- | XVII- | XVIII |
Week Fifteen: August 7 - August 11
This week we are plotting results! Retrospective analysis gives this week a C-.
Plotting the first set of results was a complete disaster. It appeared that not only were the actions/states picked by the
algorithm not deterministic, nor did they reach a global optimum but, even worse, didn't even converge most of the time!
The original idea was to say that the system of equations convereged if the P(s) stabilizes from one interation to another. And while
this was the only thing we checked for, things were chaotic, but terminated. Once I added a check to see whether P(a) stabilizes...
the algorithm never terminates. It seems that the P(a) flips values after every iteration(i.e. P(a=1) becomes P(a=0)from the previous
time step). That is messed up, good and proper.
On an equally dissapointing note, plotting P(a|past) for a specific past, over the t time steps that the algorithm is run for, is just as bad. The policy doesn't seem to converge to anything and, much like the aforementioned P(a) syndrome, the values flip very often.
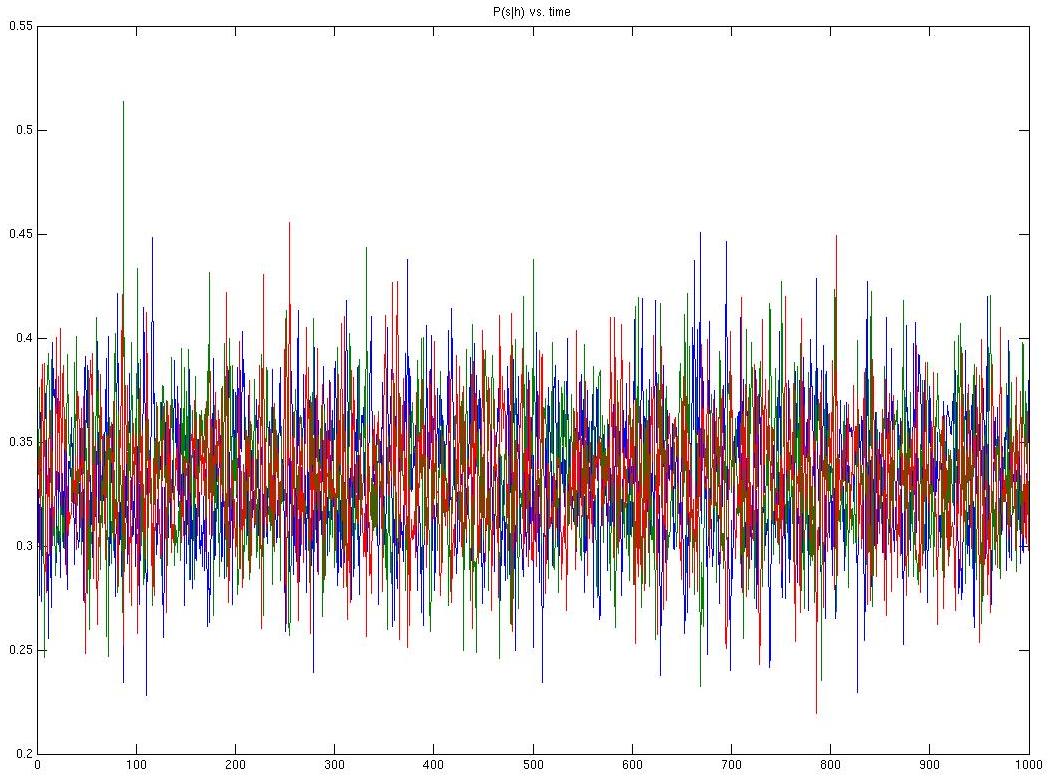
Below are the graphs. Looking at them makes me very, very angry. As you will soon notice, they are zigzags. I am convinced that if a I plotted a qvasi random probability distribution in the same way, you couldn't tell one graph from the other. What makes me angrier is the grim certainty that all this is happening because of a silly bug in the code. Bugs are poor hide-and-seek partners. This one more so.
This is the graph of P(s|past), for a specific past and the 1000 time steps that the algorithm is run for. In theory, the internal states should best approximate these pasts. Each of the three states is plotted in a different colour. It's interesting to note that, although the policy should be fairly deterministic, it insists on being anything but.
This is the graph of P(a|past), for the same specific past and 1000 time steps that the algorithm is run for. Each of the two actions(float/reset) is plotted in a different colour. I wish I could explain what this graph means, but as I'm looking at it, I'm just getting angry again. Were it to converge, it would define an action picking policy...so given a specific history, the algorithm should decide what the optimal action (the one that maximizes the mutual information between the state representation and the future, and at the same time minimizes the mutual information between the internal state representation and the past) to be taken is. Does this graph look like such a policy may be found? No, no it does not.

Bug, I shall name you Rupert. Anything that causes me this much grief deserves a name. And Rupert...I'm on to you.
*shifty eyes*.
